Stack-Based Context Management: How Playbooks Keeps LLM Context Lean and Precise
When you're working on a complex task, you don't keep every detail from every step in your active memory. You remember the current context, the overall goal, progress so far, and the gist of completed subtasks. Irrelevant details fade as you move forward.
This is exactly how AI agents should manage context, but most agent frameworks lack the structure to do this automatically. They treat context as a continuously growing list, with no natural mechanism to know when information can be safely discarded.
LLM context windows, while large, are not infinite. More importantly, even when you can fit everything into context, you probably shouldn't. Longer context means slower inference, higher costs, reduced recall, and increased risk of context poisoning.
Most agent frameworks today use the ReAct pattern (Reasoning + Acting), a loop where the LLM reasons about what to do (Thought), takes an action (tool call), observes the result, and repeats. This treats context as a linear tape that keeps growing until it hits a limit.
Playbooks takes a fundamentally different approach: stack-based context management that mirrors how humans manage task context.
The Linear Context Accumulation Problem
ReAct agents operate as a single, continuous loop. At each iteration, the LLM reasons about the problem (Thought), chooses an action or tool to call (Action), observes the result (Observation), and the cycle repeats. All of this gets appended to context, which is sent to the LLM for the next iteration.
Here's what the context looks like after executing a few steps:
- system prompt
- step 1
- step 2 (tool call result)
- step 3
- step 4
- step 5 (loaded large text file)
- step 6
- step 7 (tool call result)
- step 8
- step 9
- step 10
- step 11
- step 12
Each step may include agent responses, tool call results, intermediate reasoning, and more.
This creates several predictable problems:
-
Context accumulates indefinitely until the agent runs out of space, at which point it must forcibly compact or summarize, potentially losing important information.
-
Everything stays in context equally, regardless of relevance. That API call from 50 steps ago? Still using tokens. That intermediate calculation? Still there.
-
No structural markers exist to signal when information can be safely removed. The framework has no way to know that certain information was only needed for a subtask that's now complete.
-
Compaction is expensive and lossy. When the agent runs out of context, it must spend tokens and time summarizing thousands of tokens, and that summarization can drop details you later wish you had.
The result: slower execution, higher costs, lower quality reasoning, and increased fragility.
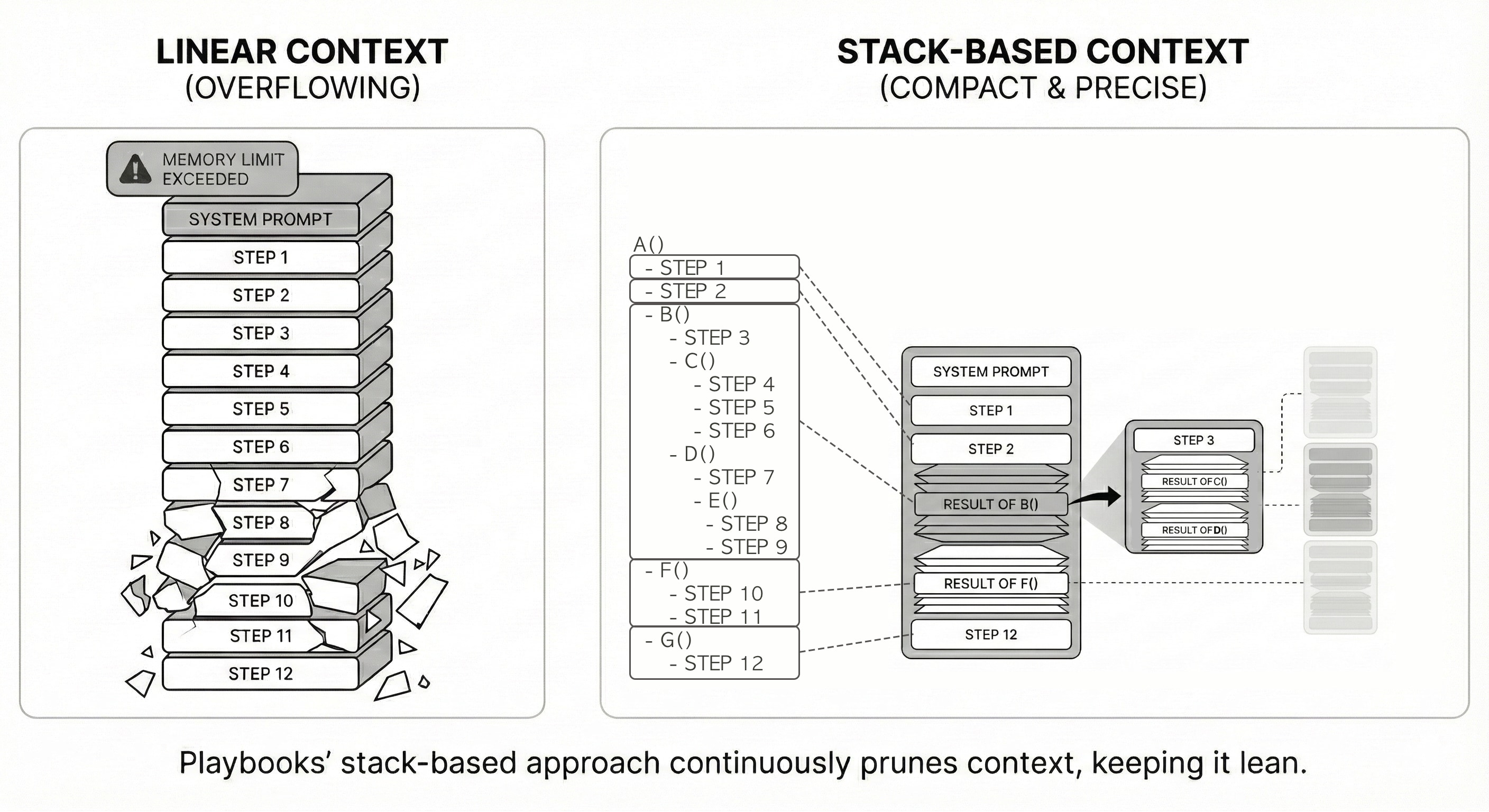
The Stack-Based Approach
Now consider the same sequence of 12 steps, but structured as a program with nested playbook calls (playbooks are like functions—reusable, composable units of work):
A()
- step 1
- step 2 (tool call result)
- B()
- step 3
- C()
- step 4
- step 5 (loaded large text file)
- step 6
- D()
- step 7 (tool call result)
- E()
- step 8
- step 9
- F()
- step 10
- step 11
- G()
- step 12
Here's the key insight:
When a playbook completes and returns, it provides a compact summary of its execution along with any return values. The detailed steps it performed are no longer needed by the caller.
Any large, intermediate artifacts loaded by the playbook (files read, large tool call results, etc.) can also be cleared from context. This leads to a significant reduction in context size.
For example, when C() completes after executing steps 4, 5, and 6, those execution details are cleared from context. The caller B() receives only C()'s result summary. When B() itself completes, its entire execution trace (including step 3, C()'s work, and D()'s work) gets compacted into a single result summary for its caller A().
By the time G() executes step 12, playbooks B() and F() have already completed and their detailed execution traces have been compacted. The context now contains:
- system prompt
- step 1
- step 2 (tool call result)
- result of B() (compact summary of B's execution)
- result of F() (compact summary of F's execution)
- step 12
Instead of 13 items (system prompt + 12 steps), the context now has just 6 items—and some of them are significantly smaller. Steps 3–11 were automatically compacted because they were part of completed playbook calls.
This mirrors how humans work. When you complete a subtask, you don't remember every detail of how you did it—just the outcome. Stack-based context management brings this natural efficiency to AI agents, automatically managing what stays in context and what can be safely discarded.
The benefits compound as workflows grow more complex:
- Smaller context means faster LLM inference and lower API costs
- Better recall because models generally do better with shorter, focused context
- Reduced context poisoning as irrelevant information is automatically compacted
- Continuous optimization rather than periodic, forced compaction
Why Only Playbooks Can Do This
Most agent frameworks can’t implement automatic stack-based context management because they lack the architectural foundation. Frameworks like LangGraph, AutoGen, and CrewAI typically use Python or JavaScript control flow to orchestrate LLM calls. The host language has its own call stack, but that structure doesn’t automatically map onto what should (and shouldn’t) persist in the LLM’s prompt.
Playbooks is different. Playbooks executes natural lanaguge programs, not orchestration code. Each playbook is a semantic unit that compiles to Playbooks Assembly and executes with its own stack frame. The runtime has the structural information needed to manage context intelligently—it knows when a playbook is called, when it returns, and what context can be safely compacted.
This is only possible when you treat LLMs as semantic CPUs executing structured programs, rather than as text generators in a loop. Stack-based context management is a natural consequence of this design.
Stack-based context management is a core feature of Playbooks. Check out the documentation for more details on building efficient multi-agent systems.
Playbooks AI is an open source Software 3.0 application framework.